AI (人工智能): 配置
AI警报过滤
要在Agent DVR中设置警报过滤器,请确保已配置AI服务器,然后按照以下步骤操作:
- 配置并启用运动检测器。为了最小化CPU使用率,请使用简单检测器。确保至少定义了一个区域来覆盖您想要监视的区域。
- 在警报选项卡中,将模式设置为仅动作并启用警报。
- 在对象识别选项卡中启用对象识别。将模式设置为检测到运动,选择一个模型,然后点击查找以选择要检测的对象,如人、狗、汽车等。
- 在选项卡菜单中转到动作,为事件AI:发现对象添加一个动作。
选择区域以指定要检测对象的位置,例如,为您的车道和道路选择不同的区域。例如,选择车道区域只有在那里检测到汽车时才会触发警报。
在任务下,点击添加以创建一个警报任务。点击两次确定。
Agent DVR将在运动检测时处理AI对象识别。如果在所选区域中检测到指定对象,它将触发一个动作以引发警报。如果没有选择区域,将触发任何区域的警报。
要进行持续的AI对象识别而无需运动检测触发,请将对象识别中的模式设置为间隔。监控硬件资源的影响并根据需要进行调整。
您可以为不同区域中的不同对象配置多个动作。在动作中使用{AI}标签引用检测到的对象。
AI过滤器故障排除
如果AI无法有效地过滤您的录像,请考虑以下事项:
- 确保查找设置与可用选项之一匹配。
- 验证Agent左上角显示的主警报开关是否有一个关闭的挂锁,表示活动警报。
- 确认录制模式设置为警报而不是检测。
- 确保警报模式设置为仅动作。
- 尝试降低对象识别下的置信度级别。
- 检查/logs.html以查看错误消息,可能指示服务器问题或网络阻塞。
- 监视AI服务器性能,并确保它不会导致系统超载或超时。
- 如果AI检测到所有对象类别,则可能表示GPU问题。检查GPU驱动程序或切换到基于CPU的AI模块。
AI物体识别
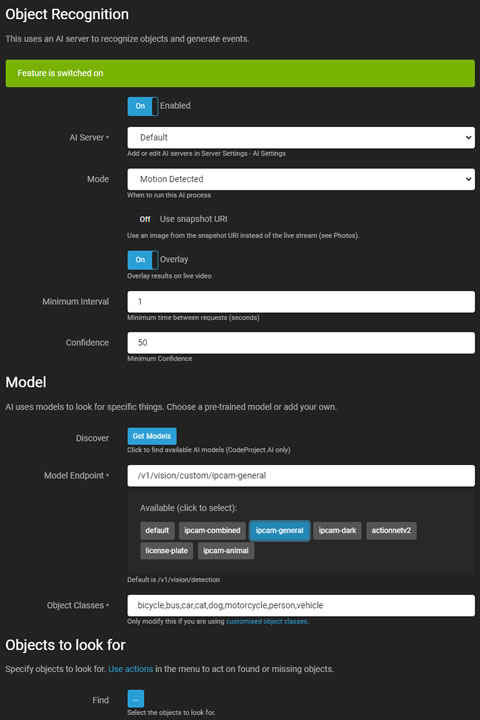
Agent DVR中的目标识别使用AI服务器(建议使用CodeProject.AI)来识别视频中的特定物体,并可以生成事件、触发警报,或作为运动警报的过滤器。
- 启用:切换以启用或禁用AI过程。
- AI服务器:从已配置的服务器中选择,或使用默认选项。
- 模式:选择AI过程的触发器。
- 运动穿越:如果AI服务器宕机并且过滤警报,则允许警报通过而不进行过滤。
- 使用快照URI:使用摄像机的高分辨率帧而不是当前的实时流帧。
- 调整大小模式:在将图像发送到AI服务器之前,调整图像的大小以减少负载并提高响应时间。
- 叠加:在实时视频流上显示AI结果。
- 颜色:叠加的颜色。此设置控制所有AI功能的叠加颜色。
- 最小间隔:设置服务器请求之间的最小时间。
- 置信度:设置识别物体的最小置信水平。
- 检查角落:有关更多详细信息,请参阅检查角落。
模型
- 发现:从服务器检索已安装的模型(特定于CodeProject.AI)。
- 模型终端:选择可用的模型或使用默认终端。
- 物体类别:自动填充相关类别或手动输入。
- 查找:指定AI要检测的物体。
- 忽略静态物体:忽略在同一位置重复发现的物体。
自定义模型
要将自定义模型添加到CodeProject.AI,请将模型文件复制到指定的目录。通过“发现”按钮访问它,但手动将对象列表添加到物体类别中。
通过编辑目标识别模块设置来更改模型存储的目录。
操作
目标识别生成AI:发现物体和AI:未发现物体事件,用于操作。
照片
有关照片的信息,请参见照片。
AI场景识别
Agent DVR 中的场景识别使用 AI 服务器(CodeProject.AI 推荐)来识别您的摄像头正在查看的一般场景,并且可以生成事件、发出警报,或者作为运动警报的过滤器。
- 已启用:切换以启用或禁用 AI 过程。
- AI 服务器:从您配置的服务器中选择,或使用默认选项。
- 模式:选择 AI 过程的触发器。通过将其设置为 None 并调用triggerScene 来仅通过 API 触发。
- 运动穿透:如果 AI 服务器宕机并过滤警报,则允许警报通过而不进行过滤。
- 使用快照 URI:使用摄像头的高分辨率帧而不是当前的实时流帧。
- 调整大小模式:在将图像发送到 AI 服务器之前调整图像大小,以减少负载并改善响应时间。
- 覆盖:在实时视频流上显示 AI 结果。
- 最小间隔:设置服务器请求之间的最小时间。
- 置信度:设置识别对象的最小置信水平。
需要查找的场景
点击按钮以选择365个可用场景进行查找。您可以选择多个场景以触发警报。
操作
场景识别会生成用于操作的AI:场景识别事件。
照片
有关照片的信息,请参见照片。
请求人工智能
Agent DVR使用AI服务器(OpenAI/ Claude等)来回答关于摄像头图像的人类可读问题。然后可以生成事件,触发警报,或作为运动警报的过滤器。您需要在服务器设置 - AI服务器 - 询问AI 中完成设置。
您可以在本地服务器的/logs.html中查看日志,以查看何时发送请求。将服务器设置 - 日志记录 - 日志级别设置为Info。
- 已启用:切换以启用或禁用AI进程。
- 提供商:选择要用于处理图像的AI提供商。提供商需要在服务器设置 - AI服务器中配置。如果选择默认值,则将使用第一个配置的提供商。
- 模式:选择AI进程的触发器。通过将其设置为无并调用triggerAskAI来仅通过API触发。
- 运动穿透:如果AI服务器宕机并且过滤警报,则允许警报通过而不进行过滤。
- 使用快照URI:使用摄像头的高分辨率帧而不是当前的实时流帧。
- 调整大小模式:在将图像发送到AI服务器之前调整图像大小,以减少负载并提高响应时间。
- 叠加:在实时视频流上显示AI结果。
- 最小间隔:设置服务器请求之间的最小时间。
AI消息
- 消息:在这里输入您对AI的问题。一些示例:
- 如果在这张图片中看到火,请回复FIRE。如果看到一只狗坐在沙发上,请回复DOG。如果门是开着的,请回复DOOR。如果满足多个条件,请用逗号分隔。
- 如果工作台上的机器灯是红色的,请回复ALERT
- 如果警车停在车道上,请回复POLICE
- 如果地板上有邮件或包裹,请回复MAIL
- 如果看起来有人闯入了我的房子,请回复BREAKIN
- 查找:输入您已指示AI回复的标签。例如FIRE,DOG,DOOR
- 不重复:忽略上次调用AI返回的标签
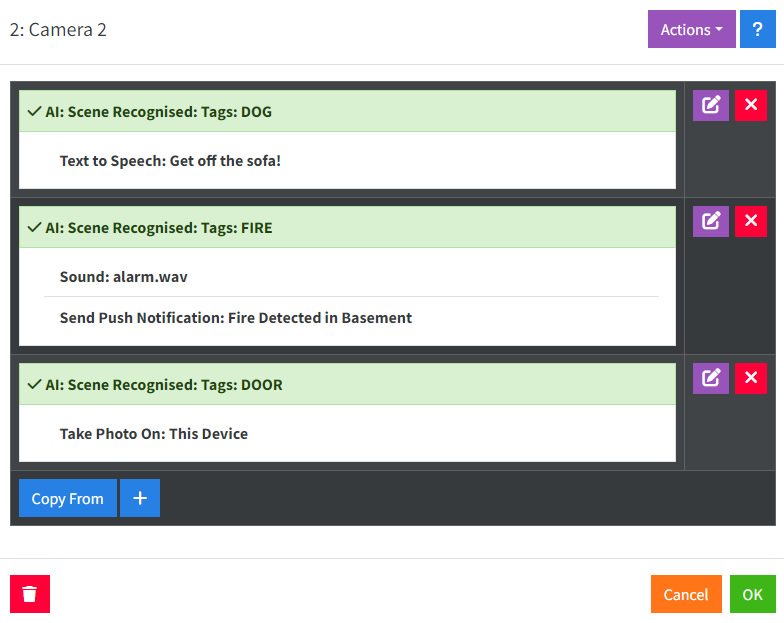
如上所述,您可以要求消息中满足多个条件,并设置处理每个结果的操作。
操作
场景识别生成询问AI:积极结果事件,用于操作。
照片
有关照片的信息,请参见照片。请注意,AI目前尚未返回有关图像中物体位置的空间数据,因此裁剪和静态检测目前无法使用。
AI照片
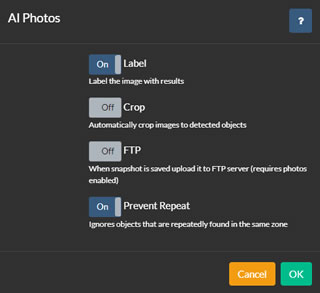
AI处理可以在识别到物体时捕获照片,提供保存、裁剪、FTP上传等选项。
要配置此功能,请在编辑摄像头时,转到每个AI配置选项卡底部的照片选项。启用照片并点击进行配置。
- 标签:Agent在图像上叠加方框并标记检测到的物体。
- 裁剪:Agent将图像裁剪到每个检测到的区域,并保存多个图像,每个区域一个。
- FTP:将保存的图像上传到摄像头配置的FTP服务器。
- 防止重复:Agent避免保存同一物体的多个副本,直到其离开运动区域。
询问 AI:描述
从 v5.8.2.0+ 开始,您可以使用人工智能来描述Agent DVR从摄像头捕获的图像在警报事件中。然后,此描述将与UI中的警报一起存储。要设置此功能,请配置 询问AI 以用于您的摄像头,并在 描述 下方查看底部的选项。
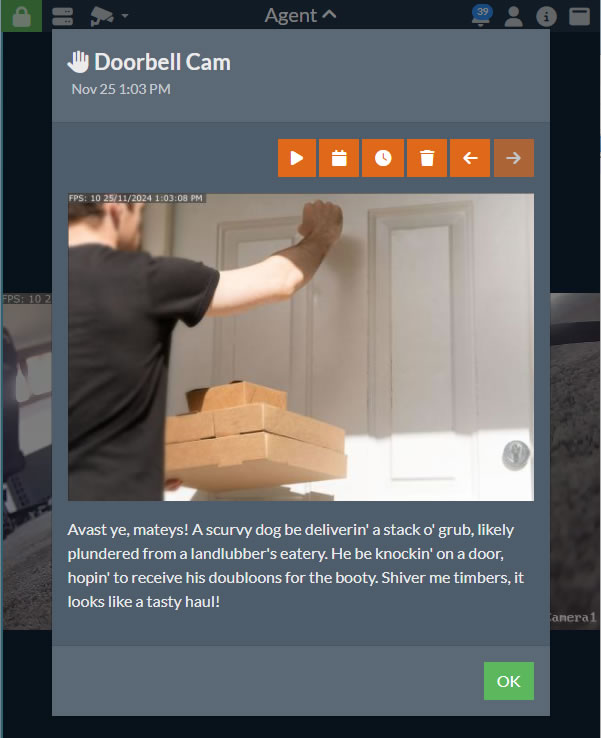
- 提示: 输入要与您的图像一起发送到AI服务器的提示。默认为"描述此图像中正在发生的事情的简短句子"。您也可以尝试一些有趣的内容,例如"用海盗语描述正在发生的事情",就像我们在上面的图像中使用的那样。
- 接下来,请转到 警报 选项卡并勾选 描述 选项。
请注意,您需要启用 询问AI。如果您只希望它描述警报图像,请将 模式 设置为“无”。
一旦您让它注释您的图像,您可以将其与 操作 系统集成,以进行 AI:描述响应已收到。您可以在此操作的任务中使用 {MSG} 和 {AIJSON} 进行其他集成。
LPR或ALPR
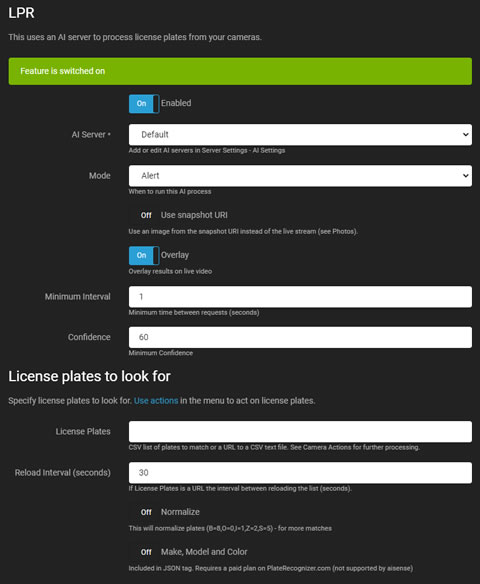
LPR(车牌识别,也称为ALPR / ANPR)利用AI服务器(推荐:CodeProject.AI和PlateRecognizer.com)从视频中识别和读取汽车的车牌。它生成事件,触发警报,或作为运动警报的过滤器。
- 启用:切换以启用或禁用AI过程。
- AI服务器:从您配置的服务器中选择,或使用默认选项。Agent通过CodeProject.AI或PlateRecognizer.com支持LPR。
- 模式:选择AI过程的触发器。
- 使用快照URI:选择来自相机的高分辨率帧,而不是当前的实时流帧。
- 叠加:将AI结果叠加到实时视频流上。
- 最小间隔:设置服务器请求之间的最小时间间隔以减少负载。
- 置信度:定义识别车牌的最小置信水平。
- 检查角落:有关详细信息,请参阅检查角落。
- 车牌:输入逗号分隔的车牌列表或包含车牌的CSV文件的URL。Agent将为这些车牌生成车牌识别和车牌未识别事件,可以触发操作。
- 重新加载间隔:设置从URL重新加载车牌列表的频率。
- 标准化:调整常常被错误识别的车牌以提高匹配度。
- 品牌、型号和颜色:仅在使用支持这些功能的PlateRecognizer.com付费计划时启用。免费计划中不包括这些功能。详细信息将包含在Agent Actions的{AIJSON}中。
操作
LPR生成AI:车牌已识别和AI:车牌未识别事件,可在操作中使用。
照片
有关照片的信息,请参阅照片。
AI人脸识别
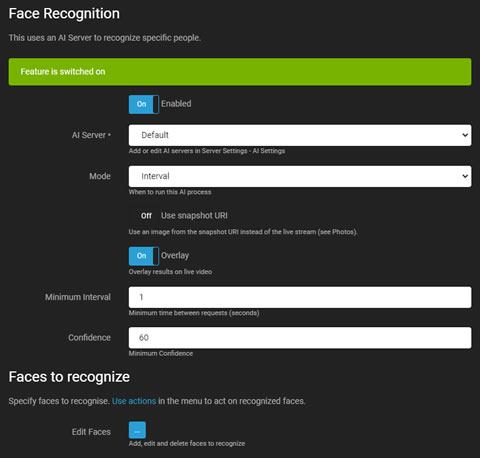
人脸识别利用AI服务器(推荐:CodeProject.AI)来识别视频中的特定人脸。它可以生成事件、触发警报,或作为动态警报过滤器。可以通过摄像机添加、编辑或删除人脸,也可以通过上传图片进行操作。有关更多信息,请参见本选项卡中的编辑人脸。
- 启用:切换以启用或禁用AI处理。
- AI服务器:从已配置的服务器中选择,或使用默认选项。
- 模式:选择AI处理的触发方式。
- 使用快照URI:选择从摄像机获取高分辨率帧而不是当前实时流帧。
- 叠加:将AI结果叠加到实时视频流上。
- 最小间隔:设置服务器请求之间的最小时间间隔以减少负载。
- 置信度:定义识别人脸的最小置信水平。
- 检查角落:有关更多详细信息,请参见检查角落。
- 编辑人脸:上传图片到服务器数据库进行识别。确保每张图片中只有一个人脸可见且清晰定义。
操作
人脸识别生成AI:人脸识别成功和AI:人脸识别失败事件,供操作使用。
照片
有关照片的信息,请参见照片。
AI音频识别
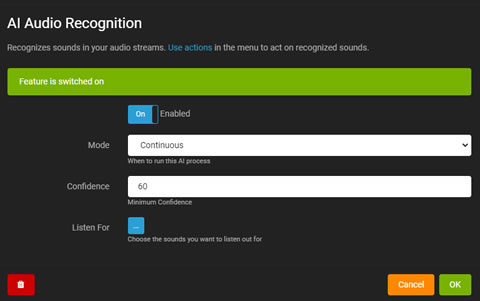
Agent DVR中基于AI的音频识别可以响应来自麦克风或音频流的已识别声音。从服务器设置 - 数据 - AI音频模型(需要iSpyConnect.com账户)下载模型文件以进行设置。
您需要编辑麦克风设置来设置音频识别。如果您有一台带有音频流的摄像机,您可以通过编辑摄像机并选择音频选项卡,然后点击“配置”来访问音频设置。
- 启用:切换以启用或禁用AI进程。
- 模式:选择AI进程的触发器。
- 置信度:设置声音识别的最低置信水平。
- 叠加:在实时音频可视化上显示AI结果。
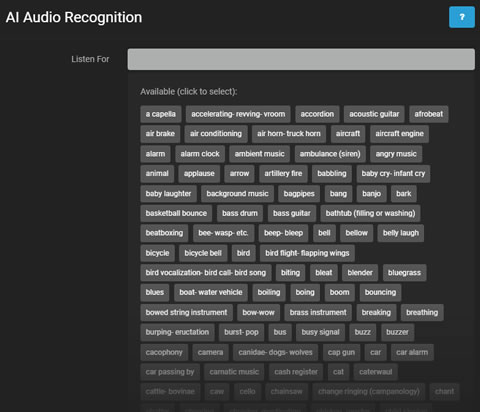
- 监听:选择AI要检测的特定声音。
点击监听显示可用于检测的声音。根据需要选择声音。
使用操作 AI:声音识别来执行声音被识别时的任务。
音频识别还可以用于过滤警报,类似于摄像机。
将操作添加到AI事件
Agent DVR 通过 AI 进程生成事件,可以触发操作。例如,对象识别生成“找到对象”和“未找到对象”的事件。Agent 中的每个 AI 系统都会产生独特的事件。
这些事件可以触发各种操作,例如触发警报、使用对象标签调用 URL、执行程序或将消息发布到 MQTT 服务器。在操作中使用标签 {AI} 表示标签,或使用标签 {AIJSON} 表示来自 CodeProject.AI 的完整 JSON 响应。